동글동글 라이프
5. SubKey List 본문
Nk Record 밑의 Subkey list 들은 하위 목록들을 나열해주는 역활을 합니다.
Subkey List 까지 뽑았다면 Registry 구조 복구의 전체적인 밑그림이 그려지며
파일 구성의 절반 이상이 끝났다고 할 수 있습니다.
결국은 Tree 구조로 되어 있으므로 재귀적으로 함수가 호출이 되는 부분을 주목하여 봐주세요 :)
아!! 월요일입니다!
말이 필요없는 월요일.. 그냥 푹~ 쉬고 싶은 월요일이지만 강좌는 멈추지 않습니다!ㅋ
소스를 잘 짜기 외해서는 기존의 공개된 소스를 어려움 없이 볼 줄 알고
코드를 짜는 사람의 내면의 고민을 같이 공유 할 수 있는 스킬을 익혀야 합니다.
그러므로 창의적으로 소스를 짜는 능력과, 코드를 세부적으로 분석하는 있는 스킬
두개를 다 골고루 키워야 한다는 것이 저의 생각입니다. ( 너무 기본적인 이야기죠? ㅋㅋ )
그럼 이제 Subkey List를 공부해 볼까요~~
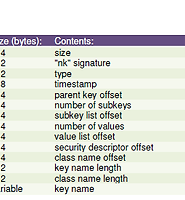
SubKey List는 서브키들의 숫자와 그 값들의 정보를 포함하고 있습니다.
SubKey List 는 "lf" 와 "lh" 그리고 "ri" 와 "li" 형식으로 2가지 타입이 있습니다.
"lf"와 "lh"는 subkey 들의 주소, Subkey들의 이름 또는
Subkey들의 문자 체크섬들 중 4자리를 포함하고 있습니다.


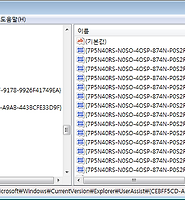
위와 같이 "lf" 값 뒤에 하위 Subkey 가 1개 있다는 것을 알 수 있고
subkey의 주소와 4개의 subkey 체크섬 문자 값을 확인 할 수 있습니다.
if ($nk{no_subkeys} > 0) {
my $nt = _getNodeType($nk{ofs_lf} + $ADJUST);
if ($nt == 0x666c || $nt == 0x686c) { # lf = 0x666c , lh = 0x686c
my %lf = readLfList($nk{ofs_lf} + $ADJUST);
foreach my $ofs_lf (keys %lf) {
parseNkRecords($name."\\".$nk{keyname},$ofs_lf + $ADJUST);
}
}
}
|
먼저 parseNKRecord 에서 subkey의 갯수가 0개 이상일 때 노드의 타입을 읽어 올 수 있습니다.
하위의 노드 타입이 lf 나 lf 일 때 하위의 nk record 들의 정보들을 뽑아 올 수 있습니다.
이렇게 뽑은 nk record의 정보를 다시 parseNKRecord 함수를 재귀적으로 호출하여
하위키들을 계속 뽑아 가는 형태입니다.

위에 보시는 것처럼 Parent NK 밑에 Subkey-List 가 존재하고
그 밑에 Child NK 들이 쭉~ 나열되어 있는 그림이 코드로 구현이 되었습니다.
# lf/lh 의 주소를 읽어와서 하위 nk Record의 리스트를 뽑는다.
sub readLfList {
my $offset = shift;
my $record;
my $num_bytes = 4;
seek($reg,$offset,0);
my $bytes = read($reg,$record,$num_bytes);
if ($bytes == $num_bytes) {
my($id, $no_keys) = unpack("SS",$record); #id 는 lf/lh 입니다.
seek($reg,$offset + $num_bytes,0);
$bytes = read($reg,$record,(2 * 4 * $no_keys));
my $iterations = ($bytes/4);
my $step = 1;
my $temp;
my %lf;
# 4개의 문자를 읽어온다.
foreach my $i (0..($iterations - 1)) {
my $str = substr($record,$i*4,4);
if ($step%2) {
$temp = unpack("L",$str);
}
else {
$lf{$temp} = $str;
}
$step++;
}
return %lf;
}
else {
print "readLfList bytes read error: ".$bytes;
return;
}
}
|
readLfList는 Offset 을 hash 값으로 뽑아오게 되며,
이 hash 의 갯수가 하위 키의 갯수라는 것을 알 수 있습니다.

두번째로는 타입이 "ri" 일 경우 다른 Subkey들의 리스트에 대한 주소를 가르키고
"li"일 경우 Subkey의 주소를 나타냅니다.
이 말은 즉! 읽어와야 하는 갯수가 하나인지 여러개인지 차이라 보시면 됩니다 :)
if ($nt == 0x6972) { # ri = 0x6972
my @ri = readRiList($nk{ofs_lf} + $ADJUST);
foreach (@ri) {
parseLiRecords($name."\\".$nk{keyname},$_ + $ADJUST);
}
}
elsif ($nt == 0x696c) { # li = 0x696c
parseLiRecords($name."\\".$nk{keyname},$nk{ofs_lf} + $ADJUST);
}
|
parseNKRecord 에서 ri 인지 li 인지에 따라 리스트로 반환해서 하나씩 주소 형식으로 읽거나
바로 아래의 주소를 읽어 오면 되는 코드입니다.
# ri 의 사이즈만큼 주소를 읽어와 리스트로 반환한다.
sub readRiList {
my $offset = shift;
my $record;
seek($reg,$offset,0);
my $bytes = read($reg,$record,4);
my ($id,$num) = unpack("SS",$record);
seek($reg,$offset + 4,0);
$bytes = read($reg,$record,$num * 4);
return unpack("L*",$record);
}
# li record들의 주소가 nk record 나 subkey 일때 다시 재귀적으로 탐색한다.
sub parseLiRecords {
my ($name,$offset) = (@_);
my @li_list = readRiList($offset);
foreach my $ofs_nk (@li_list) {
my $nt = _getNodeType($ofs_nk + $ADJUST);
if ($nt == 0x6b6e) {
parseNkRecords($name,$ofs_nk + $ADJUST);
}
elsif ($nt == 0x696c) {
parseLiRecords($name,$ofs_nk + $ADJUST);
}
else {
printf "**Unrecognized node type : 0x%x\n",$nt;
}
}
}
|
readRiList 와 paserLiRecords를 서로 호출하면서 데이터를 구성하는 코드입니다.
이제 오늘 배운 내용을 이전 코드와 함께 아래에 전체 소스를 정리해 보겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
| use strict;
use warnings;
my $ADJUST = 0x1004;
my $file = shift || die "You must enter a filename.\n";
open my $reg, '<', $file or die "cannot open [$file] file: $!";
my ($node,$offset) = locateRecord($ADJUST);
my $nt = _getNodeType($offset);
if ($nt == 0x6b6e) { # 'nk' record 일 경우 파싱을 시작
parseNkRecords("",$offset);
}
else {
printf "Node not an nk node: 0x%x\n",$nt;
die;
}
close $reg;
# nk 의 root key 값을 찾는 코드
sub locateRecord {
my $offset = shift;
my $record;
seek($reg,$offset,0);
while(1) {
read($reg,$record,4);
my ($tag,$id) = unpack("SS",$record);
if ($tag == 0x6b6e && $id == 0x2c) {
# print "nk record located.\n";
return("nk",$offset);
}
$offset = $offset + 2;
seek($reg,$offset,0);
}
}
# offset으로부터 2byte를 읽어와 unpack 을 사용하여 node의 ID를 얻는 방법
sub _getNodeType {
my $offset = shift;
my $record;
seek($reg,$offset,0);
my $bytes = read($reg,$record,2);
if ($bytes == 2) {
return unpack("S",$record);
}
else {
print "_getNodeType error - only $bytes read.";
return;
}
}
# nk record 들을 파싱하는 부분입니다.
sub parseNkRecords {
my ($name, $offset) = (@_);
my %nk = readNkRecord($offset);
print $name."\\".$nk{keyname}."\n";
print "LastWrite time: ".gmtime(getTime($nk{time1},$nk{time2}))."\n";
=subkey infomation 정보는 출력에서 제외 시켰습니다
print "Number of subkeys : ".$nk{no_subkeys}."\n";
print "Pointer to the subkey-list : ".$nk{ofs_lf}."\n";
print "Number of values : ".$nk{no_values}."\n";
print "Pointer to the value-list for values : ".$nk{ofs_vallist}."\n";
print "Pointer to the SK record : ".$nk{ofs_sk}."\n";
print "Pointer to the class name : ".$nk{ofs_classname}."\n";
print "Key name length : ".$nk{len_name}."\n";
print "Class name length : ".$nk{len_classname}."\n";
=cut
if ($nk{no_subkeys} > 0) {
my $nt = _getNodeType($nk{ofs_lf} + $ADJUST);
if ($nt == 0x666c || $nt == 0x686c) { # lf = 0x666c , lh = 0x686c
my %lf = readLfList($nk{ofs_lf} + $ADJUST);
foreach my $ofs_lf (keys %lf) {
parseNkRecords($name."\\".$nk{keyname},$ofs_lf + $ADJUST);
}
}
elsif ($nt == 0x6972) { # ri = 0x6972
my @ri = readRiList($nk{ofs_lf} + $ADJUST);
foreach (@ri) {
parseLiRecords($name."\\".$nk{keyname},$_ + $ADJUST);
}
}
elsif ($nt == 0x696c) { # li = 0x696c
parseLiRecords($name."\\".$nk{keyname},$nk{ofs_lf} + $ADJUST);
}
else {
printf "***Unrecognized node type : 0x%x\n",$nt;
}
}
}
# nk record를 읽어온 뒤 각각의 변수들로 저장시킨다.
sub readNkRecord {
my $offset = shift;
my $record;
my %nk = ();
seek($reg,$offset,0);
my $bytes = read($reg,$record,76);
if ($bytes == 76) {
my (@recs) = unpack("SSL3LLLLLLLLLL4LSS",$record);
$nk{id} = $recs[0];
$nk{type} = $recs[1];
$nk{time1} = $recs[2];
$nk{time2} = $recs[3];
$nk{time3} = $recs[4];
$nk{no_subkeys} = $recs[6];
$nk{ofs_lf} = $recs[8];
$nk{no_values} = $recs[10];
$nk{ofs_vallist} = $recs[11];
$nk{ofs_sk} = $recs[12];
$nk{ofs_classname} = $recs[13];
$nk{len_name} = $recs[19];
$nk{len_classname} = $recs[20];
# key의 이름을 알아내어 저장한다
seek($reg,$offset + 76,0);
read($reg,$record,$nk{len_name});
$nk{keyname} = $record;
# 여기까지 읽은 전체 바이트의 수는 ($num_bytes + $nk_rec{len_name}) 입니다.
# 다시 말하면 nk의 76byte + nk의 keyname 길이만큼 입니다.
# 이 값들을 활용하기 위해 hash 값을 return 시킵니다.
return %nk;
}
else {
print "readNkRecord bytes read error: ".$bytes;
return;
}
}
# 2개의 4Byte time값을 64-bit NT timestamp 값으로 변환해주는 코드
sub getTime() {
my ($lo,$hi) = (@_);
my $t;
if ($lo == 0 && $hi == 0) {
$t = 0;
} else {
$lo -= 0xd53e8000;
$hi -= 0x019db1de;
$t = int($hi*429.4967296 + $lo/1e7);
};
$t = 0 if ($t < 0);
return $t;
}
# lf/lh 의 주소를 읽어와서 하위 nk Record의 리스트를 뽑는 코드
sub readLfList {
my $offset = shift;
my $record;
my $num_bytes = 4;
seek($reg,$offset,0);
my $bytes = read($reg,$record,$num_bytes);
if ($bytes == $num_bytes) {
my($id, $no_keys) = unpack("SS",$record); #id 는 lf/lh
seek($reg,$offset + $num_bytes,0);
$bytes = read($reg,$record,(2 * 4 * $no_keys));
my $iterations = ($bytes/4);
my $step = 1;
my $temp;
my %lf;
# 4개의 문자를 읽어온다.
foreach my $i (0..($iterations - 1)) {
my $str = substr($record,$i*4,4);
if ($step%2) {
$temp = unpack("L",$str);
}
else {
$lf{$temp} = $str;
}
$step++;
}
return %lf;
}
else {
print "readLfList bytes read error: ".$bytes;
return;
}
}
# ri 의 사이즈만큼 주소를 읽어와 리스트로 반환한다.
sub readRiList {
my $offset = shift;
my $record;
seek($reg,$offset,0);
my $bytes = read($reg,$record,4);
my ($id,$num) = unpack("SS",$record);
seek($reg,$offset + 4,0);
$bytes = read($reg,$record,$num * 4);
return unpack("L*",$record);
}
# li record들의 주소가 nk record 나 subkey 일때 다시 재귀적으로 탐색한다.
sub parseLiRecords {
my ($name,$offset) = (@_);
my @li_list = readRiList($offset);
foreach my $ofs_nk (@li_list) {
my $nt = _getNodeType($ofs_nk + $ADJUST);
if ($nt == 0x6b6e) {
parseNkRecords($name,$ofs_nk + $ADJUST);
}
elsif ($nt == 0x696c) {
parseLiRecords($name,$ofs_nk + $ADJUST);
}
else {
printf "**Unrecognized node type : 0x%x\n",$nt;
}
}
}
|
이제 위의 코드로 Registry Hive 파일을 분석하게 되면 재귀적으로 하위 키를 검색하면서
데이터가 쭉~~ 뽑히는 것을 확인 할 수 있습니다.
>perl rega.pl SAM
\SAM
LastWrite time: Sun Jul 4 09:33:18 2010
\SAM\SAM
LastWrite time: Sun Jul 4 09:33:19 2010
\SAM\SAM\Domains
LastWrite time: Sun Jul 4 09:33:18 2010
... 중략
\SAM\SAM\RXACT
LastWrite time: Sun Jul 4 09:33:18 2010
와우~! 이제 레지스트리값들이 모양새를 갖추기 시작했습니다!
다음장에서는 Value Record를 통해 데이터 값들을 확인하는 방법을 알아 보겠습니다 :)
'개발자 이야기 > [forensic]Winproof' 카테고리의 다른 글
| 7. UserAssist Analysis ( ROT13 ) (1) | 2012.04.11 |
|---|---|
| 6. Value Data Storage (1) | 2012.04.10 |
| 4. NK Record (0) | 2012.04.06 |
| 3. Bin Header (2) | 2012.04.05 |
| 2. Registry hive structure (1) | 2012.04.04 |